Who watches the watcher - infrastructure monitoring heartbeat


At Ragnarson we believe that monitoring every aspect of the infrastructure is crucial for a long-term maintenance of infrastructure projects. This is extremely important, it is unlikely for us to take on projects with no budget for the monitoring. But even if you set up alerts for every service, there is one aspect of the monitoring which is overlooked by many beginner engineers.
I have seen and heard many times about infrastructure failing together with monitoring. The app goes down, but the same issue that causes the app to fail also takes down the monitoring service. No one noticed until the customer called and asked why the website is down. It happened to me in the early days of my career. Now setting up additional guards for the monitoring is a mandatory feature of any monitoring system we set up.
This important topic is rarely discussed and difficult to find resources for using Google or any other search methods. In this blog post, I will discuss how you to prevent situations when your infrastructure is down and you do not notice.
There are two approaches, each has it
s own trade-offs. First is more expensive, but it is simpler to deploy. However, you may violate data protection laws choosing external monitoring provider. The second option will cost you less long-term, it is more complex and harder to deploy and you will have full control over your data location.
First case - external monitoring
Where a budget allows or time to deliver is short, we are using DataDog. It is all-in-one monitoring and alerting solution, it can monitor every aspect of your infrastructure.
It can be easily integrated with external services like PagerDuty. It can keep you awake if something bad happens to your infrastructure - you will hate it and love it at the same time.
Without getting too much into technical details, DataDog is an agent-based, push solution. This means, there is a process running on each server, it is gathering data from all the services every minute and sends them to DataDog HQ.
Below you can see the default ‘Process’ type alert. If there is no agent process reporting for a given host for longer than 2 minutes - trigger an alert. In our case, the alert will be passed to PagerDuty.
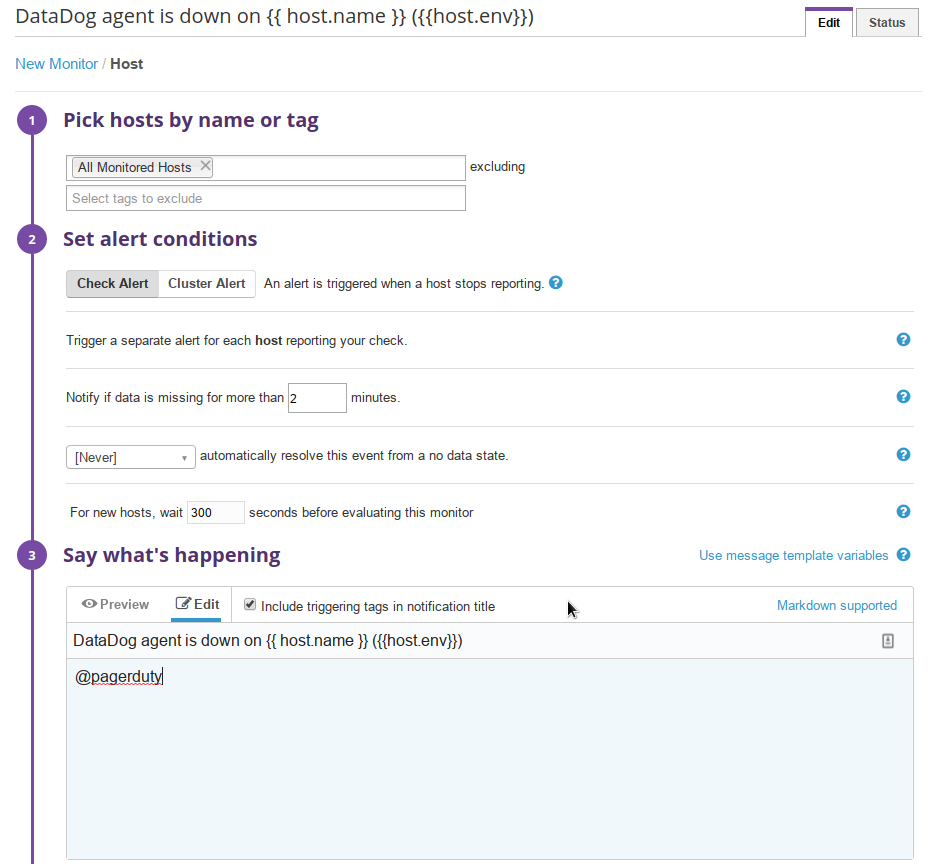
I am cheating a little bit here and I have done nothing exceptional. DataDog has a built-in watchdog if it detects there is no new data.
If you are running critical systems and you have to be an extra paranoid you can also check DataDog status page. There is an option to subscribe to their status in various ways - phone, webhook, email, RSS.
If you use something else than DataDog. A tool with the status page from the past, without convenient notification options, you can always try to integrate it over Zapier.
Self-hosted monitoring
DataDog requires some hefty budget and you may be restricted by various national or health-related data laws. Or you simply prefer in-house solutions.
Internally, we are experimenting with an on-premise monitoring solution based on Prometheus. From our point of view, it seems to be the best tool suited for metrics-based monitoring and alerting. It has a big community and version 2.0 was released recently. With some great improvements, especially in resource usage 'department'.
In case of an in-house monitoring, there is no upstream status page, we are the single user of the service. If a monitoring node goes down you will not even know. If a service goes down (or is not operating as supposed to) there will be no alert.
I did not find any obvious agent check-ups, like in case of DataDog. So I have started with simple google searches for generic ideas how people may handle ‘monitoring the monitoring’. Picks from the top of my head were:
- monitoring heartbeat
- verify monitoring system
- ensure monitoring software is running
- monitoring dead man switch (Do not ask me how I have connected monitoring with bomb trigger. This is not a search phrase which will be used by most of the people)
Unfortunately, my google-fu was poor. Most of the results were about ‘real life’/heart monitoring. I have even learned a new trick - the AROUND keyword. However, in conjunction with various self-hosted monitoring solutions did not give me any good results. Only the last phrase gave me some ideas how to ensure my monitoring is up and running. Yet, it was still far from a ready-made solution.
I left the idea for a few days to grow on me. It was not urgent since we are just experimenting with Prometheus.
After a few days, I have stumbled on this short five-step overview on #monitoring at Hangops slack (a highly recommended community). It describes how to configure Prometheus with PagerDuty and DeadManSnitch. It was the biggest eye-opener. The best approach to my issue I was able to find. I do not know who is the author, but he/she deserves a medal.
It is not my goal to copy the slides, see it by yourself. The basic idea applies almost to any on-premise monitoring. Fire an automatic alert periodically. If there are no alerts, our alerting software does not work, call on-duty team. Since we are using PagerDuty anyway it is almost a perfect fit. Of course, there is no ideal solution which covers all the corners, even this has some strong and weak points:
Advantages:
- It can be adapted to most self-hosted monitoring/alerting solutions.
- Zapier or Cronitor can be used instead of DeadManSnitch.
- If you are not tied to PagerDuty, there are some alternatives like VictorOps or OpsGenie, which has Heartbeat Monitoring out of the box.
- It is not HA, it does not need more than one server.
Disadvantages:
- You are adding another point of failure to the infrastructure.
- Requires extra services, which adds a complexity and an implementation/maintenance cost.
- If you run ‘Failure Friday’, it is another point on the checklist.
- It is not HA, it may fail as well.
Overall I think it adds a reasonable level of the complexity for what it gives. I would not go anywhere further - the watcher who watches the watcher who watches the watcher is enough ;-)
I hope now you have a better overview how to 'watch the watcher' in your infrastructure. Anyway, if something seems to be unclear, please leave us a comment. Yet, if you would like us to set it up for you, give us a call or send us an email.