"How we built Ruby PaaS - Part I: Overview of our stack"


I would like to share with you the details of how we built Shelly Cloud, our platform for hosting Ruby applications, and how it works.
This is the first post of the series on our blog, in which I'll present you with an introduction to the company and an overview of our stack. You will also find links to future posts as and when we publish them:
- Part I - Overview of the stack
- Part II - Gem and web interface
- Part III - API
- Part IV - Architecture, servers and virtualization
About the company
I'll begin by giving you a little background on how our business started. Shelly Cloud began as an internal project of Ragnarson, the Ruby and JavaScript software house. Our goal was to create a common solution to deploy client applications. The first attempt was made in early 2010 and in the beginning it was nothing more than a collection of Chef cookbooks. In 2012, we decided to give the system API, a user interface and transform it into the regular product. Today, six people work on it full time, on a daily basis and three more part-time. We are bootstrapped, profitable and didn't get any external investment.
Some facts:
- 35+ bare physical servers, most of them are Intel Xeon 1x E5-2650v2 8c/16t with 2,6 GHz+/3,4 GHz and 128 GB DDR3 ECC 1600MHz of memory
- 260+ apps running with over 400 virtual servers
- Our users made over 100 000+ deployments
- Two server regions which work separately: Europe and North America
Shelly Cloud is built to run independently from the server providers, but for now we buy hardware from two providers: OVH and Hetzner. We don't use Amazon EC2, essentially because we don't want to add another layer of virtualization. Client virtual servers are only run in the OVH network.
The stack
Let's start with the diagram:
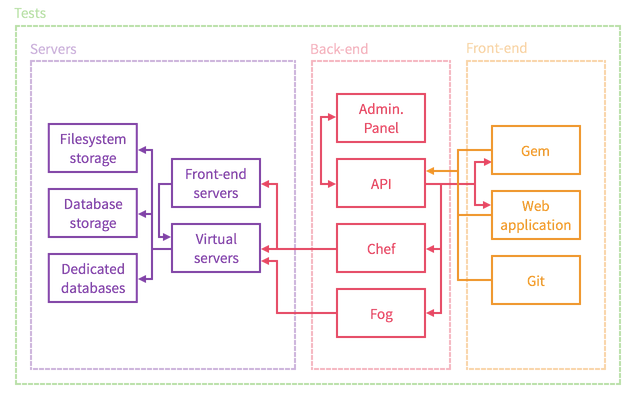
We can split the whole stack into four main segments:
- Tests: which verify stability and quality of the whole platform
- Front-end: where customers manage their account and applications
- Back-end: administration panel and API which communicates with front-end and configures servers using Chef
- Servers: front-end servers, physical servers where virtual servers are run, and several servers for specific additional services
Tests
We have our own custom solution which tests the entire stack. It's built with RSpec and Capybara and tests everything from typing a shell command like shelly start in the terminal, to spawning a configured virtual server with a working Rails app. I won't get into too many details here, mainly because we already published a blog post about it - "How we perform system integration tests". What is important here is that the test suite is run automatically every night, on both the production environment for both regions and on our staging. Moreover, we have a web application which allows us to browse the builds history, and send notifications to our internal chat room every time tests fail. We can start the test manually as well, even on our local machines. Right now, we have over 40 different test scenarios. Besides all this, we have regular unit tests in each element of the stack.
Front-end
There are three ways in which users can interact with our platform: command line interface, web application and Git.
The first of these, command line interface (CLI), is written in Ruby, based on the Thor toolkit, and distributed as a regular gem via RubyGems. It is important to note that our CLI is open-sourced, so if you want to you can browse its code or even contribute to it. CLI has 32 main commands and most of them have supplementary subcommands. The basic thing which gem is doing under the hood is communicating with the API. We use rest-client to handle this.
Secondly, the web application is a website which you browse - shellycloud.com. We use it as a landing page, to publish documentation, for blogging, and to allow clients to manage things which aren't that obvious in CLI, e.g. to edit billing details or for displaying cloud statistics. The funny thing is the site is deployed on Shelly Cloud itself. We used Rails 4.2 with Slim + Sass + CoffeeScript combo to built it. We are also using AngularJS, but without JS routing, just to implement interactive elements as components. Webapp doesn't have a direct connection to the database. For people interested in gems, we use Her for API mapping and Postmarkdown as a blog engine.
The last way to interact, Git, provides an easy route for users to do deployments. On our side, we don't use anything more than git hooks and a server for repositories storage.
Back-end
The main part of the back-end is our API. Besides the front-end described above, it interacts with three more elements:
- Administration panel
- Chef, to configure and manage physical servers
- Fog, to communicate with cloud computing software
API is the Rails application with almost 110 gems. It's quite big and monolithic, but we regularly extract code from API to smaller services. To create JSON responds, we use Rails serializers. The main database is in PostgreSQL, but we also use Redis for Resque to run background jobs and MongoDB for our custom logs streamer. API is running from the rest of the applications on its own server with Apache and Passenger. We use Capistrano to manage the deployment process.
Servers
System administration isn't just the core of our infrastructure, it's also the core of our business. Basically, people pay for us to handle maintenance, upgrades, configurations, monitoring, and automation on servers for them. As I mentioned, we use Chef to manage physical servers and our Chef repository has uploaded over 100 cookbooks. It allows us, for example, to set up and add a new node controller in less than 10 minutes, without any impact on the rest of stack. We gather stats from different services using statsd + Grafana + InfluxDB combo.
The entry point of our architecture for customer applications is the front-end server. It contains the following three services:
- NGINX which we use as a web server
- Varnish for HTTP and static files cache
- HAProxy to load balance traffic to the application servers
They are all fully duplicated with automatic failover.
To set up and administrate virtual servers, we use OpenStack. Virtual machines run only on physical servers with SSD drives and Ceph as a distributed object store and file system. The Linux distribution of our choice is Debian, and we are using aptly to manage package dependencies. Every virtual server has installed, configured and integrated by default:
- RVM to manage Ruby versions
- Fluentd for collecting logs
- Memcache for local cache
- Postfix for emails
- Monit and Eye, for monitoring purposes
Number and specification of virtual servers are chosen by the user and stored in the application's repository in a YAML file called Cloudfile. Customers can define which Ruby server, databases, background processing, or job scheduler they want to use for the app. There is also the possibility to start custom processes out of the processes supported by default. Databases are run on the same virtual servers with application processes, but databases storage is on separate machines, which also run on SSD drives with Ceph. Database storage is duplicated, and backed up regularly too. App's deployment time depends heavily on the specification, but a full deployment of a new Rails application, from git push to start a new virtual server from scratch, doesn't take more than 35s.
Besides the databases on virtual servers, we also offer databases with replication on dedicated hardware. Depending on the client's preference, they can be run directly on a dedicated physical server or on physical servers shared with other databases. In the second case, we use LXC to manage virtualization.
The last thing to mention is our filesystem storage for static files. It runs on dedicated GlusterFS cluster and is also backed up regularly.
Outsourcing
There are also some 3rd party services which we use and I want to mention:
- New Relic for server monitoring
- CircleCI as a continuous integration system
- Intercom to communicate with our users and provide support
- DNSimple and Zerigo for DNS
- PagerDuty for phone notifications about platform issues
- Braintree for credit card and PayPal payments
- GitHub for storing our code
- Pivotal Tracker as the tasks tracker
- Slack for internal communication
- Fakturownia/InvoiceOcean for invoices and accounts
- Lawyers office
To be continued…
Basically, that's all the general information. Please don't hesitate to ask questions in the comments section. As I mentioned at the beginning, please keep an eye out for the next part of this series, where I'll be explaining more about every section.